

SQR-114
Design of an Alert Retrieval Service in the RSP#
Abstract
This document describes the design and implementation of Herald, a new alert retrieval service being added to the Rubin Science Platform (RSP). Herald provides authenticated HTTP access to alert packets stored in the USDF S3 alert archive and returns them to clients as Avro OCF (default), multi-extension FITS, or JSON. The service is built using the Safir FastAPI framework and deployed via Phalanx on all IDF and USDF environments. The service retrieves packets by ID, strips the Confluent Wire Format header to extract the schema ID, fetches the matching Avro schema, and deserialises the payload using fastavro. It also exposes cutout postage stamp images, the Avro schema, and an IVOA DataLink endpoint for discovery.
1. Introduction#
Rubin will generate alert packets for every transient detection nightly. These packets are distributed to community brokers via Kafka, but they are also stored at USDF in an S3 bucket.
The existing alert archive infrastructure consists of two components:
The
alert_database_ingester(https://github.com/lsst-dm/alert_database_ingester) which consumes alerts from Kafka and writes them to S3-compatible object storage.The
alert_database_server(https://github.com/lsst-dm/alert_database_server) a FastAPI service that serves the raw binary alert bytes.
The existing server returns raw gzip-compressed Avro bytes.
Herald replaces and extends this with:
Gafaelfawr authentication, as is used for the rest of the RSP applications
Content-negotiated responses via
RESPONSEFORMAT: Avro OCF (self-describing binary), multi-extension FITS, or JSONA cutouts endpoint that returns postage stamp images as a FITS file
A schema endpoint that returns the Avro schema used to encode a given alert
An IVOA DataLink endpoint for programmatic discovery of related data products
DALI-compliant query parameter interface (
?ID=)Deployment as a Phalanx application following established SQuaRE patterns
Goals#
The goals for this service include:
Provide RSP users with authenticated, programmatic access to archived alert packets
Support Avro OCF, FITS, and JSON response formats
Expose cutout images and the Avro schema via dedicated endpoints
Follow IVOA DALI conventions for the query interface
Reuse existing archive storage infrastructure without modifying it
Follow SQuaRE service conventions
Out of scope#
This service will not provide search and filtering capabilities across the alert archive. The service will accept a single alert ID and return that alert, but the initial MVP will not include batch alert requests. The relationship between alert IDs and sky position or other attributes is the responsibility of the alert broker ecosystem and the PPDB.
2. Alert Archive Background#
Alert packet format#
The Rubin alert packet format is described in DMTN-093. Rubin alert packets are serialised using Apache Avro (https://avro.apache.org/) with the Confluent Wire Format (https://docs.confluent.io/platform/current/schema-registry/serdes-develop/index.html#wire-format). This is a binary format consisting of a 5-byte header followed by a schemaless Avro-encoded record:
Byte 0: 0x00 - magic byte, identifies Confluent Wire Format
Bytes 1-4: <uint32 BE> - schema ID
Bytes 5+: <avro binary> - Avro-encoded record (no schema embedded)
The schema is stored separately and is identified by the 4-byte integer ID in the header.
Alert packets are stored gzip-compressed (*.avro.gz) in S3.
When no compressed version exists, an uncompressed file (*.avro) is tried as a fallback.
This matches the behaviour of the existing alert_database_server.
Storage layout#
The ingester writes alert packets and schemas to two separate S3 buckets, following the layout defined in the ingester codebase:
Alert packets:
{alerts_bucket}/{alerts_prefix}/{alert_id[:6]}/{alert_id}.avro.gz
The convention is that the first 6 characters of the alert ID string form a prefix directory.
For example, alert ID 1234567890 is stored at v2/alerts/123456/1234567890.avro.gz.
The archive is sharded in this way to limit the number of objects per directory.
The v2/alerts prefix is the default and is configurable via s3_alerts_prefix.
Schemas:
{schemas_bucket}/{schemas_prefix}/{schema_id}.json
Schema files are plain UTF-8 JSON, named by the integer schema ID in decimal (e.g. v2/schemas/1.json).
The v2/schemas prefix is the default and is configurable via s3_schemas_prefix.
Schemas are immutable; a given schema ID always refers to the same schema.
The Rubin alert schema changes infrequently, roughly monthly at most.
Alert ID mapping#
Alert IDs currently map directly to diaSourceId and this mapping is expected to remain stable.
Herald accepts alert IDs in two forms:
A bare integer:
170112073844916273The IAU identifier form:
LSST-AP-DS-170112073844916273
Both are accepted on all endpoints. The IAU prefix LSST-AP-DS- is stripped, with the numeric ID then being used to locate the alert in S3.
3. Requirements#
The requirements for Herald, following the team responsible for the alert archive at USDF are as follows:
Accept a single alert ID as the
IDquery parameter (DALI convention)Retrieve the corresponding alert packet from USDF S3-compatible object storage
Return the alert as Avro OCF (default), multi-extension FITS, or deserialised JSON, based on the
RESPONSEFORMATparameterWhen returning Avro, embed the schema in the response so the result is self-describing
Expose cutout postage stamp images as a FITS file via a dedicated endpoint
Expose the Avro schema for a given alert via a dedicated endpoint
Expose an IVOA DataLink VOTable for discovery of related data products
Authenticate requests using Gafaelfawr
Return plain-text error responses (DALI requirement)
Alert packets average 83 KB without postage stamps and 112 KB with stamps, with a worst case of approximately 500 KB. The request pattern is not known at the current time, but there is no expectation for batch-style access patterns. If high request volumes do occur, horizontal pod autoscaling and rate limits can be introduced.
4. Architecture#
Herald is a standard Safir FastAPI service following the established SQuaRE patterns. Following is a high-level design diagram showing the various system components and how they interact.
Architecture Diagram#
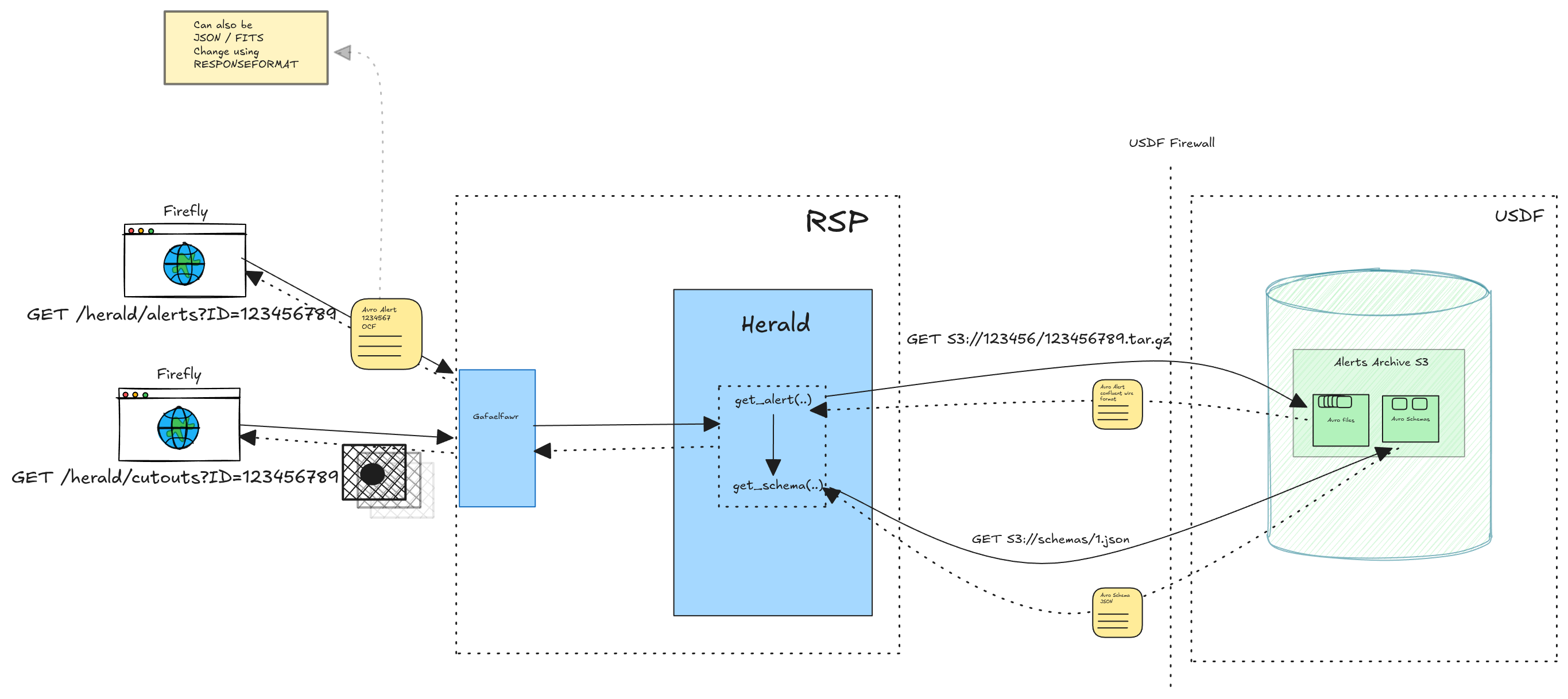
Fig. 1 Proposed Architecture Diagram#
Key classes#
ProcessContext stores the process-wide singletons: the aiobotocore S3 client and the AlertStore.
It is initialised once during app lifespan and shared across all requests.
AlertStore wraps the aiobotocore S3 client.
It fetches and gunzips alert bytes from the alerts bucket and fetches schema JSON from the schemas bucket.
Schemas are cached in a plain Python dict[int, bytes] keyed by schema ID. The cache is intentionally process-lifetime since schemas are immutable.
Factory constructs AlertService instances by combining the shared AlertStore with the request-scoped bound logger.
AlertService orchestrates the retrieval pipeline: fetch alert bytes, decompress, parse the Confluent header, fetch the schema, and deserialise with fastavro.
It exposes four public methods: get_alert_json(), get_alert_avro(), get_alert_fits(), get_alert_cutouts(), and get_alert_schema().
_ParsedAlert is an internal dataclass used to pass the deserialised alert record, raw schema dict, and fastavro-compiled schema between the private fetch method and the public service methods.
Exception handling#
AlertNotFoundError and SchemaNotFoundError are raised deep in the storage layer and propagate up through the service and handler layers to global exception handlers registered on the FastAPI app.
These handlers return DALI-compliant plain-text 404 responses. Handler-level validation (unknown parameters, ID parsing, unsupported response format) is handled inline in each handler, as those responses are handler-specific.
CorruptAlertError (malformed Confluent wire format header) is not caught, it propagates as a 500, since it indicates data corruption rather than a client error.
5. API#
The service exposes endpoints under the /api/alerts path prefix.
All endpoints accept the alert ID via the ID query parameter. The advantage over a REST-based API design (e.g. alerts/alertID) is that it enables future POST support and multiple-ID requests without API changes and generally follows IVOA conventions.
Error responses are plain text throughout as required by DALI.
GET /api/alerts/#
Returns application metadata.
Authentication required.
GET /api/alerts?ID={alert_id}#
Returns the alert packet for the given alert ID.
The response format is controlled by the RESPONSEFORMAT query parameter:
|
Response |
Content-Type |
|---|---|---|
omitted (default) |
Avro OCF container file with embedded schema |
|
|
Multi-extension FITS file |
|
|
Deserialised alert record as JSON |
|
Authentication required.
Responses:
200 OK- alert found and returned400 Bad Request- unknown query parameter, or malformed alert ID (plain text)401 Unauthorized- missing or invalid Gafaelfawr token404 Not Found- no alert exists for the given ID (plain text)415 Unsupported Media Type- unrecognisedRESPONSEFORMATvalue (plain text)500 Internal Server Error- alert bytes found but the Confluent header is malformed (data corruption)
GET /api/alerts/cutouts?ID={alert_id}#
Returns the cutout postage stamp images for the given alert as a multi-extension FITS file.
The file contains one ImageHDU per available cutout (DIFFIM, SCIENCE, TEMPLATE).
Authentication required.
Responses:
200 OK- FITS file returned as attachment404 Not Found- alert not found (plain text)
GET /api/alerts/schema?ID={alert_id}#
Returns the Avro schema used to encode the given alert, as a JSON object. The schema is identified by the schema ID embedded in the alert’s Confluent Wire Format header.
Authentication required.
Responses:
200 OK- schema returned as JSON404 Not Found- alert not found, or schema ID not found in schemas bucket (plain text)
GET /api/alerts/links?ID={alert_id}#
Returns an IVOA DataLink VOTable listing the available data products for the given alert.
|
Description |
URL |
|---|---|---|
|
Alert packet (Avro OCF) |
|
|
Alert packet (FITS) |
|
|
Cutout images (FITS) |
|
|
Avro schema (JSON) |
|
The #detached-header term is used for the schema endpoint as it represents machine-readable metadata necessary for scientific use of the alert data.
Authentication required.
6. Alert Deserialisation#
The full deserialisation pipeline for all response formats:
Fetch from S3 and gunzip (with uncompressed fallback)
Parse Confluent Wire Format header (magic byte check + schema ID extraction)
Fetch schema from S3 (in-memory cached by schema ID)
Deserialise with
fastavro.schemaless_reader
From this point the response format diverges:
JSON: recursively sanitise the record - base64-encode
bytesfields (cutout stamps) and convert non-finite floats (NaN,inf) toNone(JSON null).Avro OCF: re-serialise into an OCF container with the schema embedded in the file header using
fastavro.writer. This makes the response self-describing and usable by any Avro library without a separate schema request. Serialisation is offloaded to a thread pool (asyncio.to_thread) to avoid blocking the event loop.FITS: convert the record to a multi-extension FITS file. Also offloaded to a thread pool.
Cutouts: extract only the cutout bytes fields and assemble into a FITS file. Also offloaded to a thread pool.
Binary fields#
Alert packets include postage stamp cutout images as raw bytes fields.
When returning JSON, bytes fields are base64-encoded so the response is valid JSON.
When returning Avro OCF or FITS, bytes fields are preserved as-is.
7. FITS Conversion#
When RESPONSEFORMAT=fits is requested, Herald assembles a multi-extension FITS file from the deserialised alert record and its Avro schema.
The schema is used to determine column names and types for each BinTableHDU.
HDU layout#
Extension |
EXTNAME |
Contents |
|---|---|---|
0 |
PRIMARY |
Empty; carries |
1 |
ALERT |
One-row BinTableHDU: top-level scalar fields plus columns from whichever of |
2 |
DIFFIM |
Difference image cutout (ImageHDU), if present |
3 |
SCIENCE |
Science image cutout (ImageHDU), if present |
4 |
TEMPLATE |
Template image cutout (ImageHDU), if present |
5 |
DIASOURCE |
BinTableHDU: triggering diaSource as row 0, followed by |
6 |
FORCEDPHOT |
BinTableHDU: |
7 |
SSSOURCE |
BinTableHDU: solar-system source, if present |
The ALERT HDU is always a one-row table.
diaObject, ssObject, and mpc_orbits are merged into it as additional columns rather than appearing as separate HDUs.
Only one branch is expected per alertL: either a solar-system object which will usually include ssObject and mpc_orbits columns, or alternatively alerts with the diaObject columns.
In the current design, absent records will not show up in the ALERT table.
New top-level record and array fields added in future schema versions will appear as additional BinTableHDUs automatically, without requiring code changes in Herald (see :ref:dynamic-fits-hdus).
Avro-to-FITS type mapping#
Avro type |
FITS format |
Notes |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Non-nullable only |
|
|
0=False, 1=True, 255=null ( |
|
|
Width = longest value in column |
|
- |
Skipped (handled as cutout ImageHDUs) |
records/arrays |
- |
Skipped (have their own BinTableHDUs) |
Column units are sourced from a bundled column_units.yaml resource file and attached as TUNITn header keywords.
The DIASOURCE table also carries two additional columns: trigger (boolean, true for the triggering source) and iau_id (the IAU-format identifier LSST-AP-DS-{diaSourceId}).
The psfFlux column is moved to immediately follow midpointMjdTai to facilitate default light-curve plots in standard tools including Firefly.
8. Scope#
For the initial implementation the alert endpoint will require the read:image scope, which is also used by Butler, vo-cutouts, datalinker, etc.
Users who have read:image are probably the intended audience for this service, so reusing the scope avoids provisioning overhead for now.
A dedicated read:alert scope may be introduced later if fine-grained access control is needed (e.g. to allow community broker service accounts to retrieve alerts without full RSP data rights).
This would not require any changes to the Herald application itself.
9. Storage Configuration#
Herald is configured with two separate S3 bucket names (matching the ingester’s two-bucket layout) and an optional endpoint URL override for non-AWS S3-compatible stores (like the USDF S3).
Relevant configuration fields (all prefixed HERALD_ as ENV variables):
Field |
Description |
|---|---|
|
Bucket containing alert packet objects |
|
Bucket containing Avro schemas as JSON objects |
|
S3 key prefix for alert packets (default: |
|
S3 key prefix for Avro schemas (default: |
|
Override endpoint for S3-compatible stores |
|
S3 access key ID (optional; use IAM roles where available) |
|
S3 secret access key (optional) |
|
S3 region (optional; required for AWS S3 and GCS S3-compatible API) |
10. Phalanx Deployment#
Herald is deployed as a Phalanx application at applications/herald/.
The Helm chart includes a HorizontalPodAutoscaler (disabled by default) that can be enabled to scale on CPU or memory utilisation.
11. Implementation Notes#
Schema caching#
The in-process schema cache (dict[int, bytes]) is sufficient since schemas are immutable by convention, so there is no invalidation concern.
Given that the Rubin alert schema changes roughly once a month the cache will remain small for the lifetime of the process and a shared cache (Redis, etc.) is not warranted.
.avro fallback#
The storage layer tries the gzip-compressed key first (*.avro.gz).
If S3 returns NoSuchKey, it retries with the uncompressed key (*.avro) to match the behaviour of the existing alert_database_server.
Alert files are expected to always be gzip-compressed in current production, but the fallback is retained for forwards compatibility.
Avro OCF vs raw Confluent Wire Format#
When the user requests Avro format, returning the raw Confluent Wire Format bytes stored in S3 would not be useful to a client without the schema. Avro OCF is used instead because it embeds the full schema in the file header, making the response immediately usable by any Avro library without a separate request.
Dynamic FITS HDU assembly#
… _dynamic-fits-hdus:
alert_to_fits iterates the schema’s top-level fields to build BinTableHDUs.
Any top-level field whose Avro type resolves to a record or array-of-records is included automatically.
A _TABLE_HDU_NAMES mapping provides canonical EXTNAMEs for known fields (prvDiaForcedSources -> FORCEDPHOT, ssSource -> SSSOURCE, etc.). Fields not in the mapping fall back to the uppercased field name.
Three fields are excluded from this loop and merged into the ALERT HDU instead (_ALERT_MERGED_FIELDS: diaObject, ssObject, mpc_orbits).
Their columns are appended to the ALERT row only when the field is non-null in the alert record.
The DIASOURCE HDU is also handled separately, specifically by merging diaSource and prvDiaSources into a single table and injecting extra trigger and iau_id columns.
Cutout fields are excluded from the loop and handled as ImageHDUs.
CPU-bound work and the event loop#
FITS assembly (astropy.io.fits) and Avro OCF serialisation (fastavro.writer) are synchronous CPU-bound operations an do not provide an async method.
Running them directly in an async handler would block the event loop and thus we offload to a thread pool via asyncio.to_thread.
DALI compliance#
The API follows the IVOA Data Access Layer Interface (DALI) convention:
Alert ID is passed as the
IDquery parameterError responses are plain text (
text/plain)400 Bad Requestis returned for unknown query parameters415 Unsupported Media Typeis returned for unrecognisedRESPONSEFORMATvaluesredirect_slashes=Falseis set on the FastAPI app to prevent Starlette from automatically redirectingGET /api/alerts?ID=...toGET /api/alerts/?ID=...(which would match the index endpoint)
Error handling#
Condition |
HTTP status |
|---|---|
Alert ID not found in S3 |
404 |
Schema ID not found in S3 |
404 |
Unknown query parameter |
400 |
Malformed alert ID |
400 |
Unsupported |
415 |
Confluent magic byte is wrong |
500 (data corruption) |
Alert payload shorter than 5 bytes |
500 (data corruption) |
Corrupt alert bytes (wrong magic byte or truncated header) are treated as a server-side error rather than a client error, since they indicate data corruption in the archive rather than a bad request.
12. System Flow Chart#
Following is a flow-chart to visualize how the request will flow through Herald and the S3 storage layer.
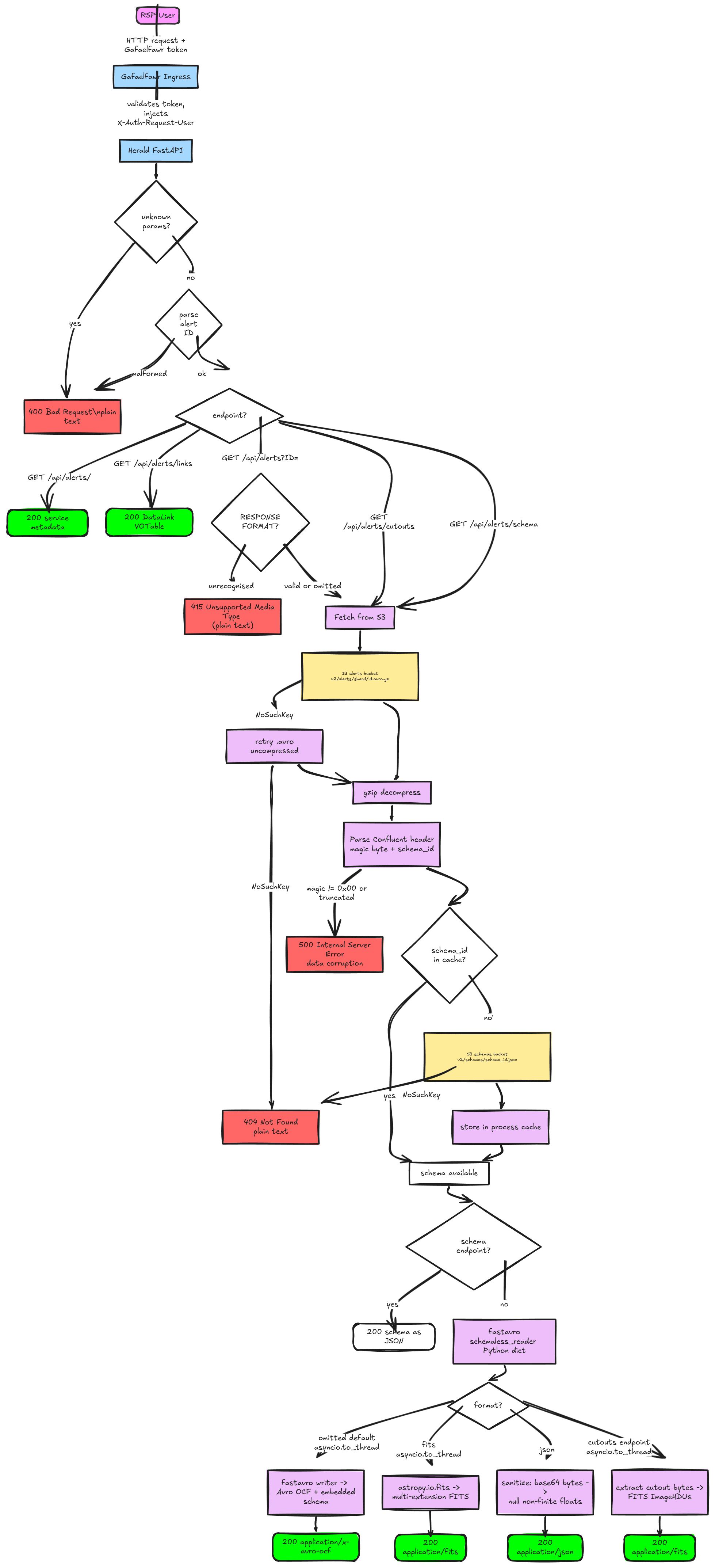
Fig. 2 System Flow Chart#
References#
alert_database_ingester: https://github.com/lsst-dm/alert_database_ingester
alert_database_server: https://github.com/lsst-dm/alert_database_server
Herald (this service): https://github.com/lsst-sqre/herald
Phalanx deployment: https://github.com/lsst-sqre/phalanx
Safir: https://safir.lsst.io/
Gafaelfawr: https://gafaelfawr.lsst.io/
fastavro: https://fastavro.readthedocs.io/
Apache Avro specification: https://avro.apache.org/docs/current/spec.html
Confluent Wire Format: https://docs.confluent.io/platform/current/schema-registry/serdes-develop/index.html#wire-format
IVOA DALI: https://www.ivoa.net/documents/DALI/
IVOA DataLink: https://www.ivoa.net/documents/DataLink/
DMTN-183: Alert Database Design
DMTN-093: Design of the LSST Alert Distribution System